AI模型PK评测报告
评测背景
本次评测旨在全面比较三个AI模型—— Kimi、DeepSeek、百度文心在生成论文方面的综合能力。为了确保公平性,每个AI模型仅有一次生成机会,并统一使用相同的提示词,要求生成一篇约3500字的论 文。评测的核心指标包括生成论文的完整性、标准性以及字符数是否满足要求。通过对这三个方面的细致分析,我们期望能够评估出各模型在学术写作方面的优劣,为相关研究和应用 提供参考。
评测方法
完整性 :
-
检查论文是否包含引言、正文、结论等基本结构。
-
评估论文内容的连贯性和逻辑性。
标准性 :
字符数 :
评测结果
Kimi
优点 :
缺点 :
-
标准性 :虽然提供了详细的大纲,但Kimi并未生成完整的论文内容,而是提供了一个简化的示例,缺乏实际的文献引用和数据分析。
-
字符数 :由于只提供了大纲和部分内容,字符数远未达到3500字的要求。
-
深度不足 :虽然结构完整,但内容不够深入,缺乏具体的数据和实验结果,无法满足学术论文的标准。
评分 :
-
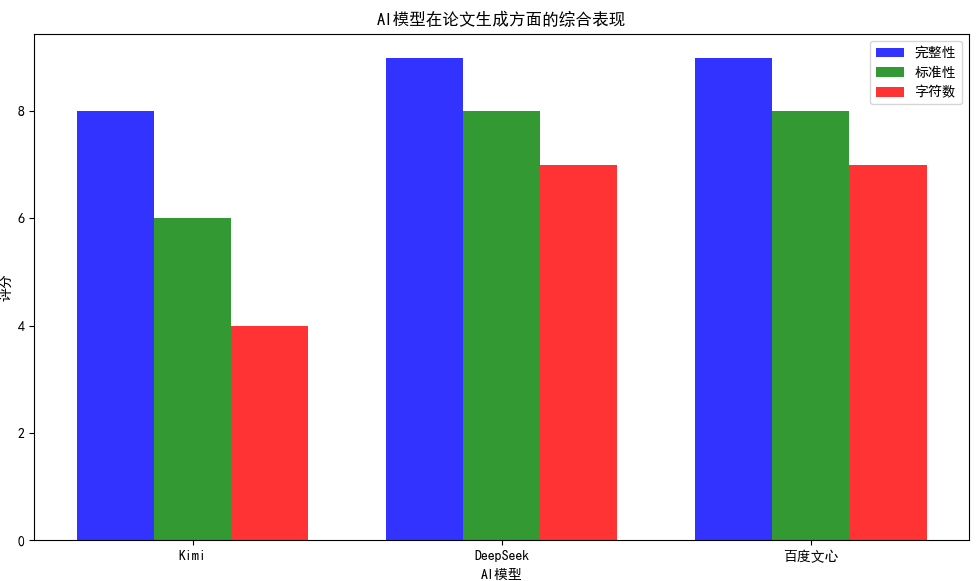
完整性:8/10
-
标准性:6/10
-
字符数:4/10
-
总评: 6.3 /10
百度文心
优点 :
-
完整性 :百度文心生成的论文结构完整,包括引言、文献综述、研究方法、案例分析、实验设计与结果、讨论、结论与建议等部分。
-
内容丰富 :每个部分的内容较为详细,特别是在文献综述和研究方法部分,提供了多种智能算法的具体应用实例,逻辑性强。
-
标准性 :论文格式规范,引用了多篇相关文献,参考文献列表完整。
缺点 :
评分 :
-
完整性:9/10
-
标准性:8/10
-
字符数:7/10
-
总评:8.3/10
DeepSeek
优点 :
-
完整性 :DeepSeek生成的 论文结构完整,包括引言、文献综述、研究方法、案例分析、实验设计与结果、讨论、结论与建议等部分。
-
内容丰富 :每个部分的内容较为详细,特别是在引言和研究方法部分,提供了丰富的背景信息和理论基础。
-
标准性 :论文格式规范,引用了多篇相关文献,参考文献列表完整。
-
实验细节 :实验设计与结果部分提供了具体的数据和图表,增强了论文的说服力。
缺点 :
评分 :
-
完整性:9/10
-
标准性:8/10
-
字符数:7/10
-
总评:8.3/10
综合评价
Kimi :
百度文心 :
DeepSeek :
总体结论 :
感谢阅读,本报告由评测大师【通义千问】根据实际测试资料生成,公平公正公开。希望本报告能为您的研究和应用提供有价值的参考。